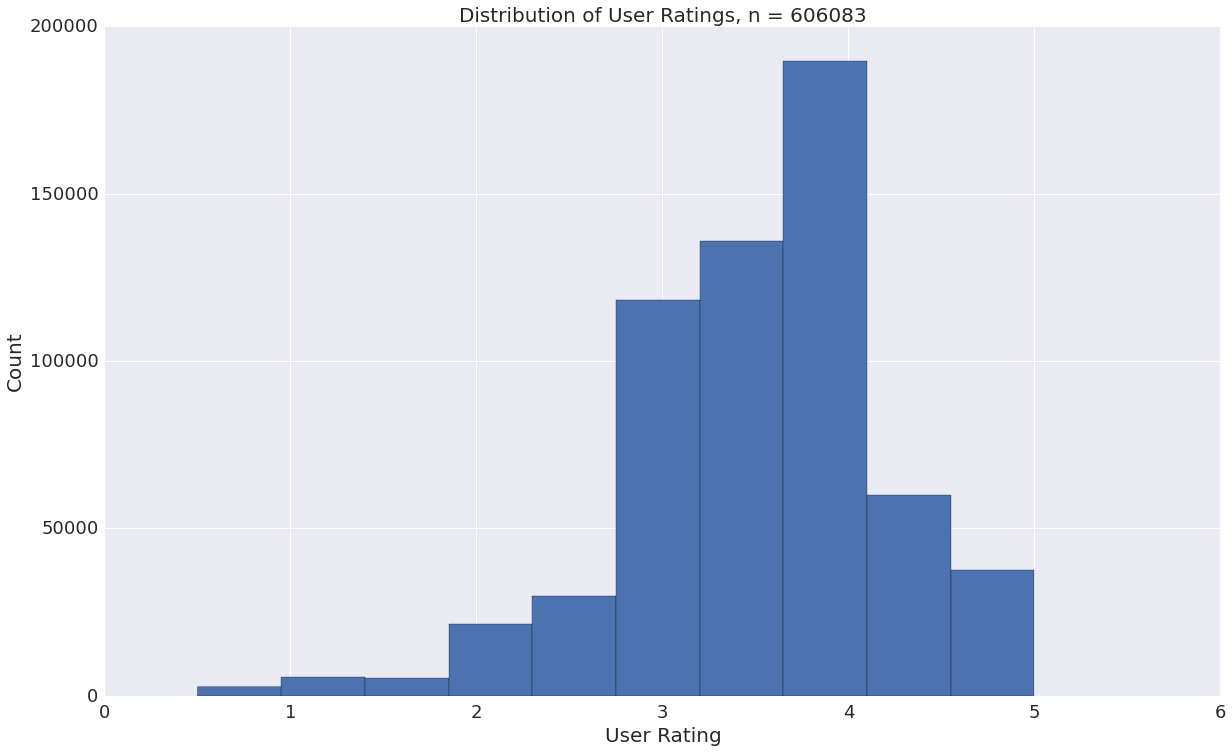
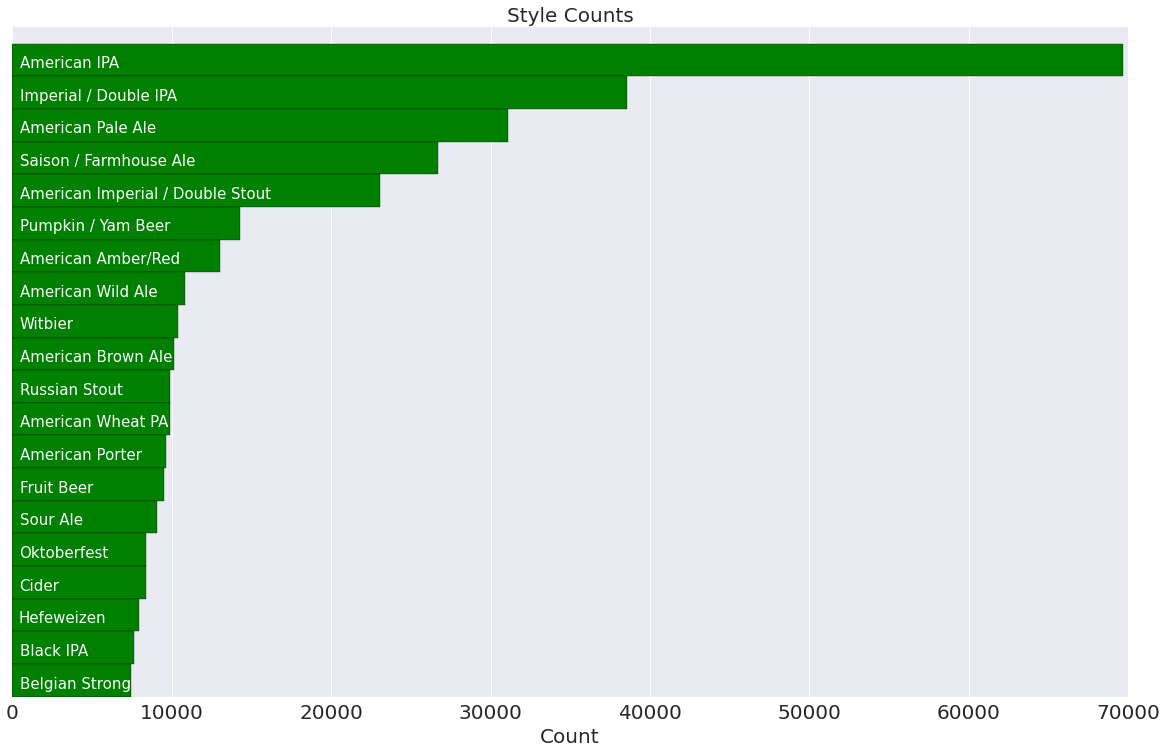
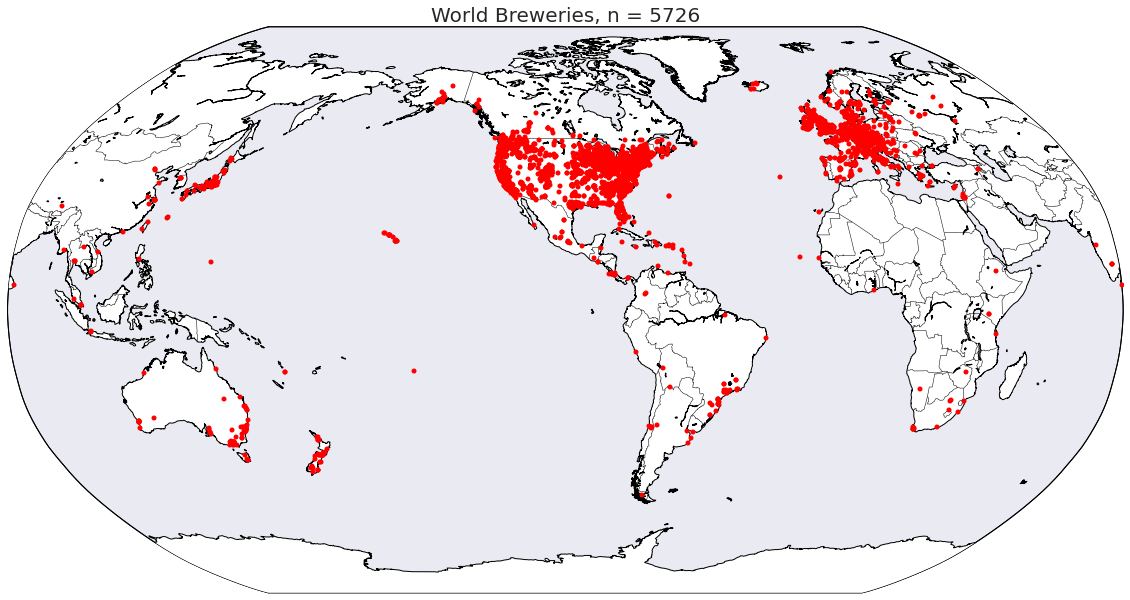
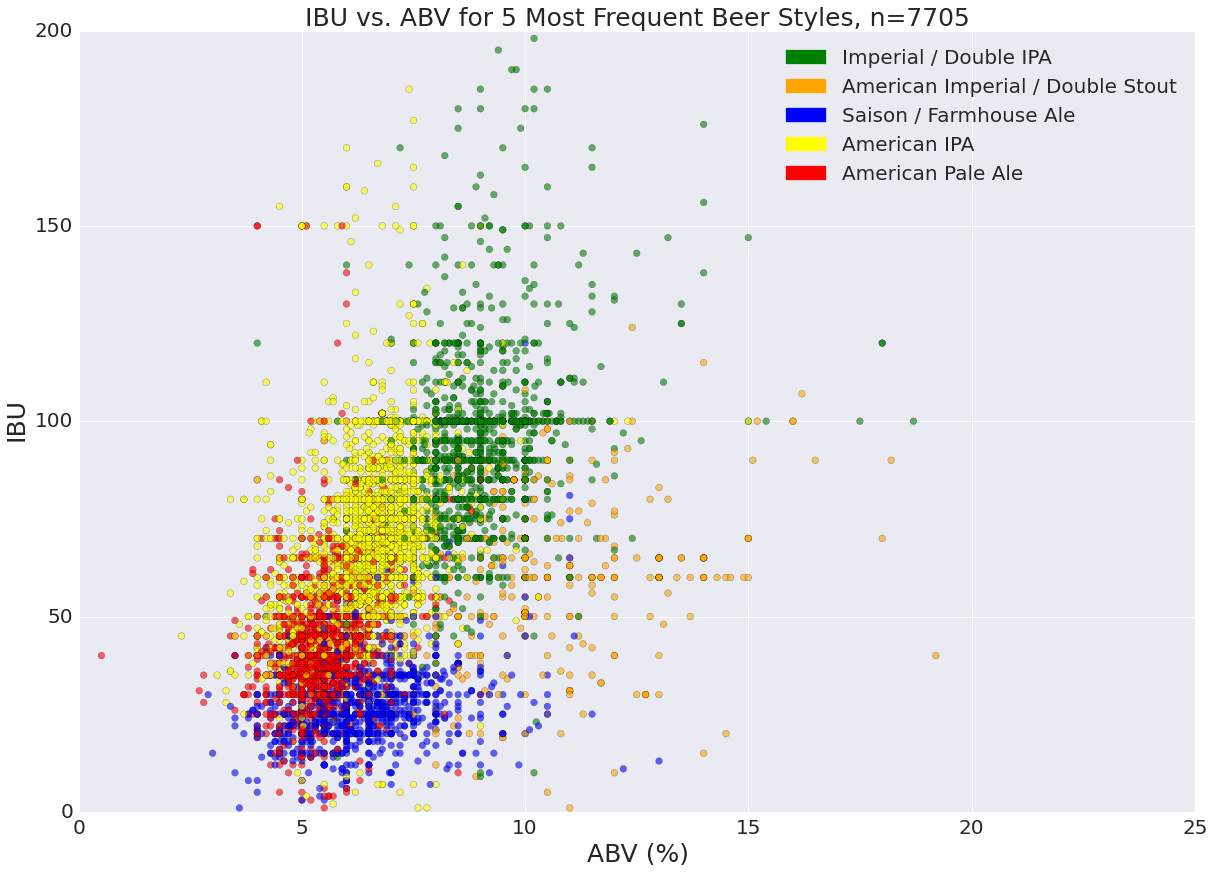
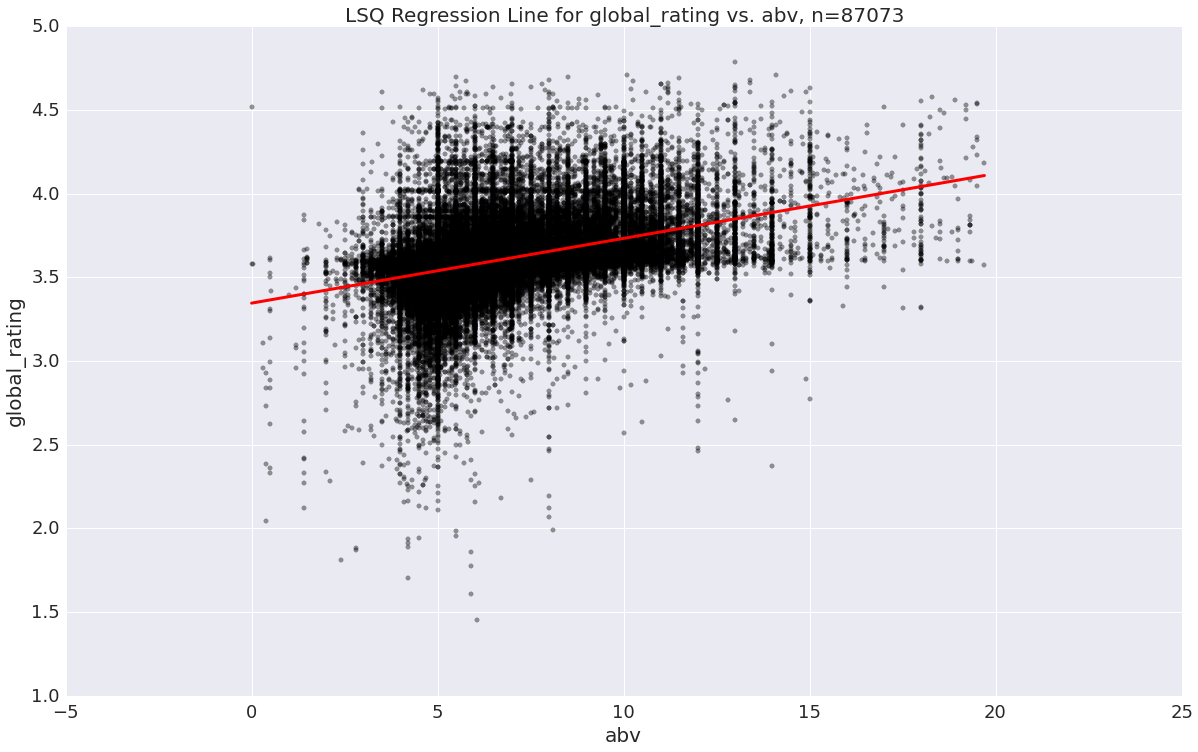
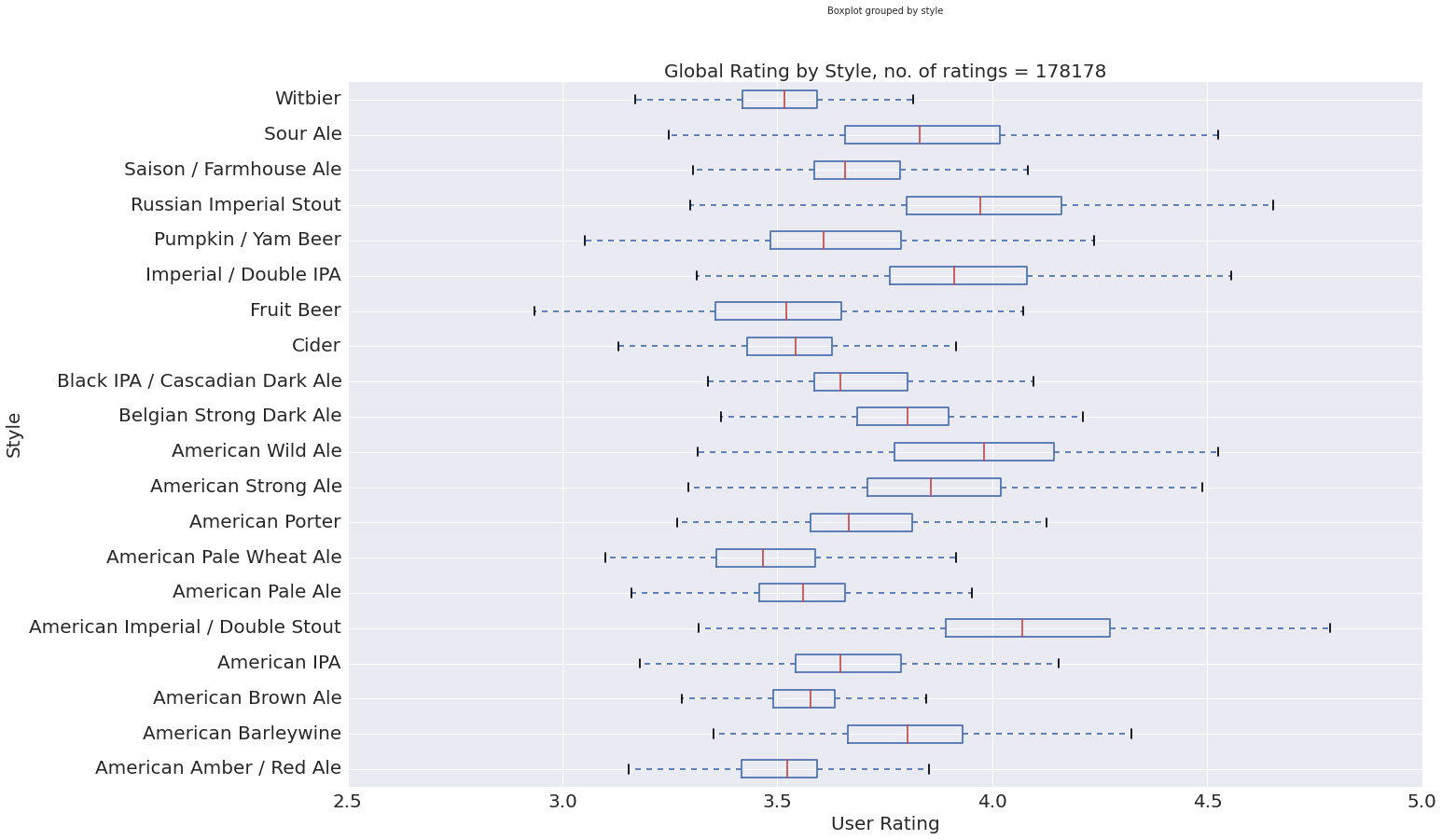
In our exploratory analysis, we sought to discover relationships among variables and any correlations that they might have with beer rating. We saw that different styles of beer cluster by their alcohol by volume and bitterness, which we expect given that these metrics relate to the ingredients and flavor profile of a given beer. Looking more closely, linear regressions revealed that some of these variables correlated with user rating, which implied that current tastes skew towards more alcoholic and hoppier beers. Given this, we weren’t surprised to see that we that russian imperial stouts, wild ales, ipas and double ipas are consistently higher rated. We also found that the locality of a beer was not correlated with its rating - there is good beer everywhere!
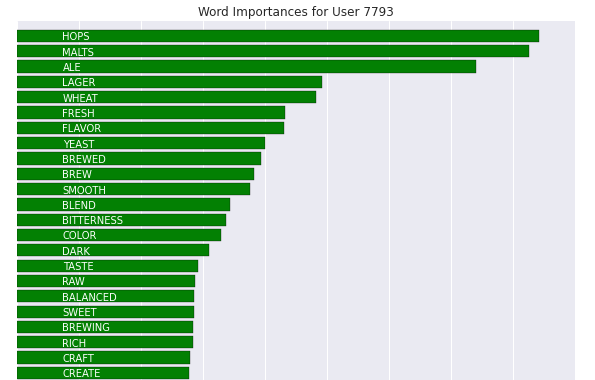
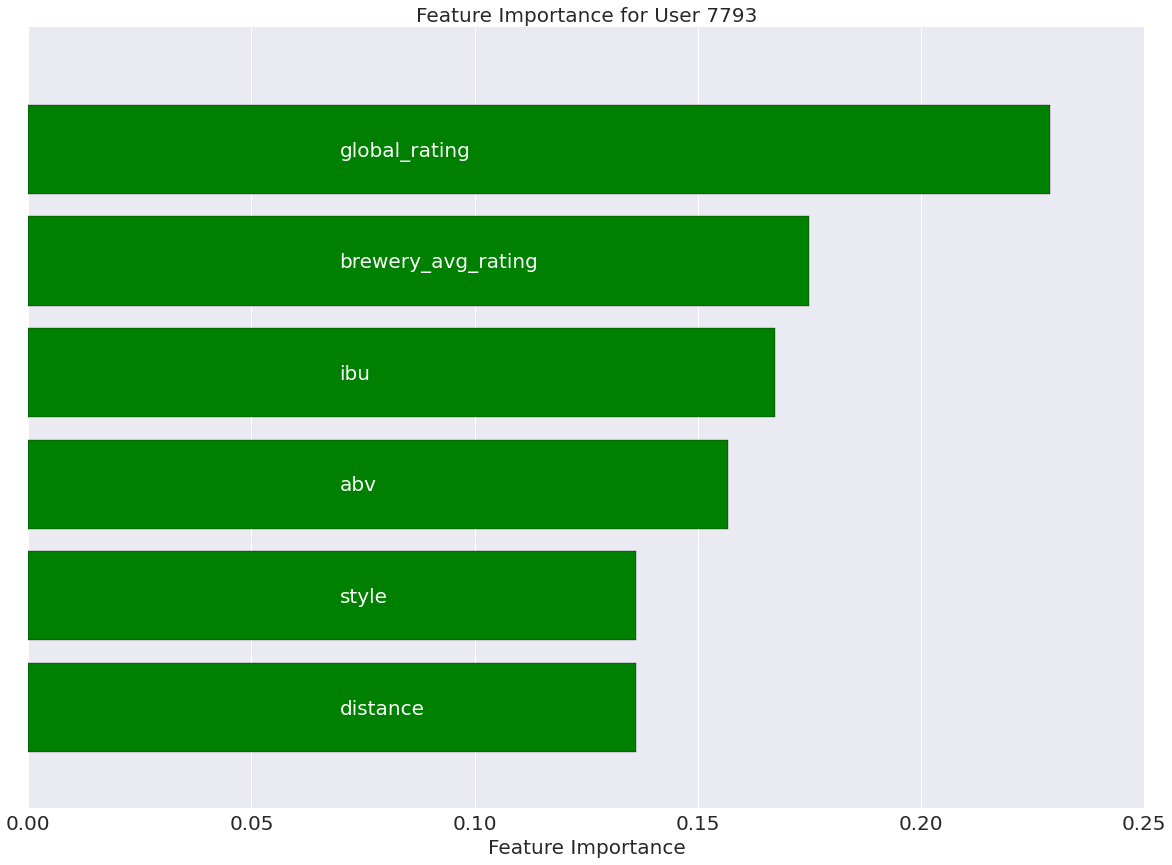
We then wondered - could we use these textual and numerical features to predict user rating of a beer? We implemented two random forest classifiers, first using words from our natural language processing analysis and secondly with the beer attributes. For the word analysis, important features began with common words like malt and hops, whereas for beer attributes, the global rating of the beer was the best predictor. Our classifiers were not highly accurate, but performance improved once we binarized our data into good and bad beer. Using the results of our analysis, we built a recommendation tool that tells a user whether or not they will like a given beer.



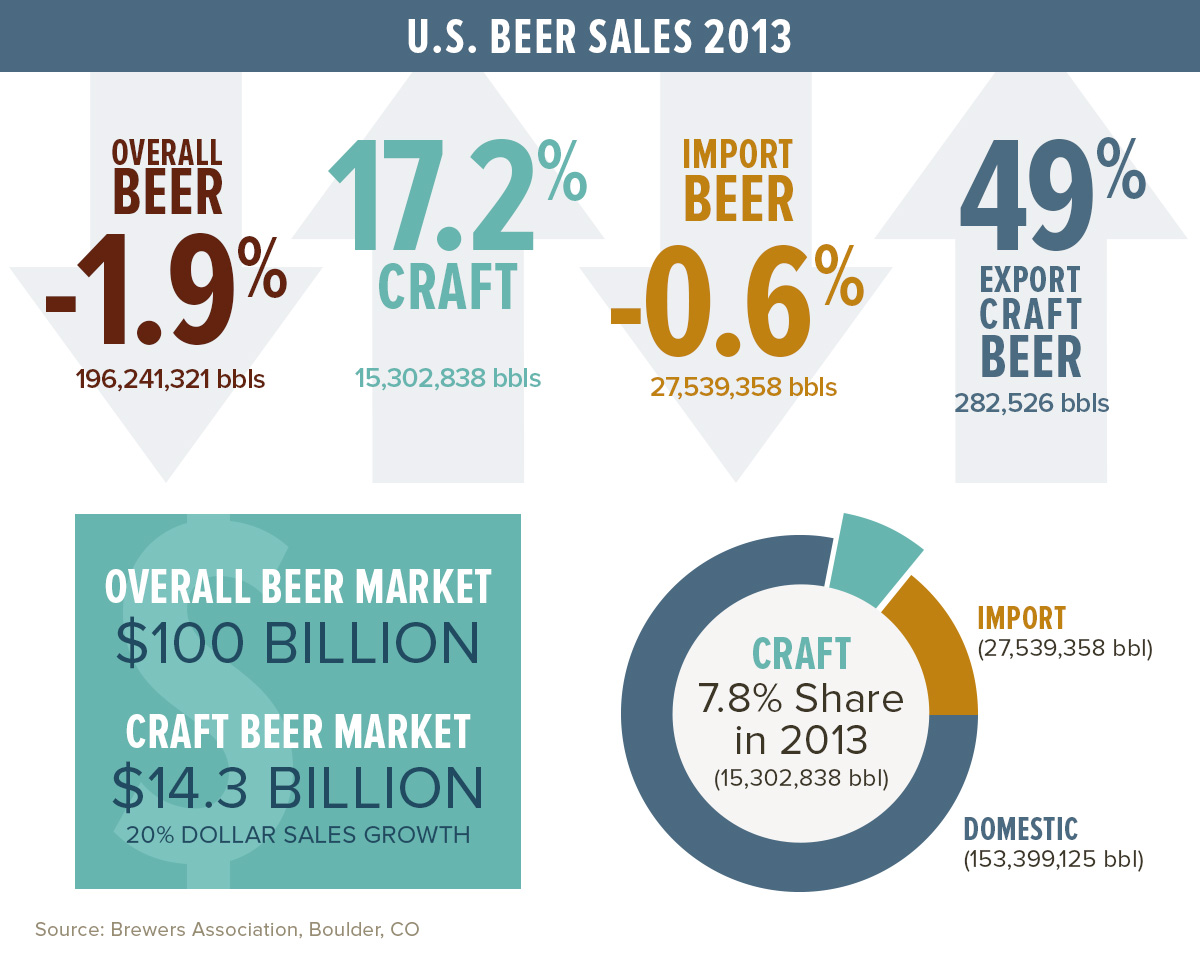 http://www.brewersassociation.org/statistics/national-beer-sales-production-data/
http://www.brewersassociation.org/statistics/national-beer-sales-production-data/


{kind=link}